In part 1 of my blog about Exchange on premises migration from Domino I talked about the challenges of working with Exchange for someone who is used to working with Domino. If only that were all of it but now I want to talk about the issues around Outlook and other Exchange client options that require those of us used to working with Domino to change our thinking.
In Domino we are used to a mail file being on the server and regardless of whether we used Notes or a browser to see that client, the data is the same. Unless we are using a local replica, but the use of that is very clear when we are in the database as it visibly shows “on Local” vs the server name.


We can also easily swap between the local and server replicas and even have both open at the same time.
In Outlook you only have the option to open a mailbox in either online or cached mode.
So let’s talk about cached mode because that’s the root of our migration pains. You must have a mail profile defined in Windows in order to run Outlook. The default setting for an Outlook profile is “cached mode” and that’s not very visible to the users. The screenshot below is what the status bar shows when you are accessing Outlook in cached mode.
![]()
In cached mode there is a local OST file that syncs with your online Exchange mailbox. It’s not something you can access or open outside of Outlook.
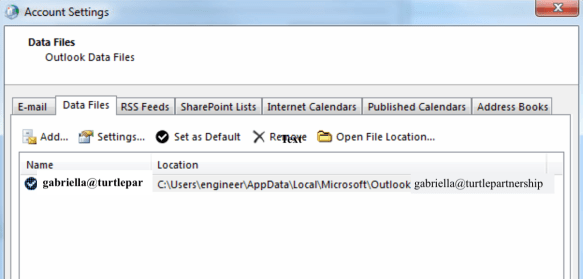
Outlook will always use cached mode unless you modify the settings of the data file or the account to disable it.
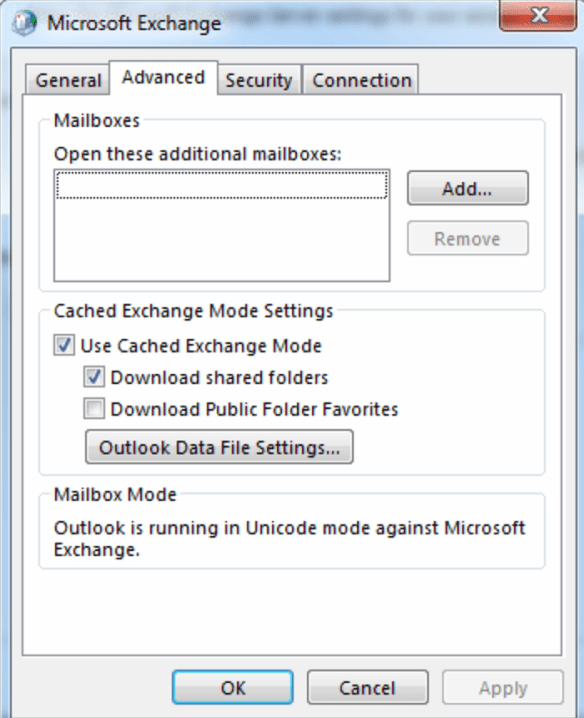
As you can see from the configuration settings below, a cached OST file is not the same as a local replica and it’s not designed to be. The purpose of the cached mail is to make Outlook more efficient by not having everything accessed on the server.
Why does this matter during a migration? Most migration tools can claim to be able to migrate directly to the server mailboxes but in practice the speed of that migration is often unworkably slow. If that can be achieved it’s by far the most efficient but Exchange has its own default configuration settings that work against you doing that including throttling of activity and filtering / scanning of messages. Many / most migration tools do not expect to migrate “all data and attachments” which is what we are often asked to do. If what we are aiming for is 100% data parity between a Domino mail file and an Exchange mailbox then migrating that 5GB, 10GB, 30GB volume directly to the server isn’t an option. In addition if a migration partially runs to the server and then fails it’s almost impossible to backfill the missing data with incremental updates. I have worked with several migration tools testing this and just didn’t have confidence in the data population directly on the server.
In sites where I have done migrations to on premises servers I’ve often found the speed of migration to the server mailbox on the same network makes migration impossible so instead I’ve migrated to a local OST file. The difference between migrating a 10GB file to a local OST (about an hour) vs directly to Exchange (about 2.5 days) is painfully obvious. Putting more resources onto the migration machine didn’t significantly reduce the time and in fact each tool either crashed (running as a Domino task) or crashed (running as a Windows desktop task) when trying to write directly to Exchange.
An hour or two to migrate a Domino mail file to a local workstation OST isn’t bad though right? That’s not bad at all, and if you open Outlook you will see all the messages, folders, calendar entries, etc, all displaying. However that’s because you’re looking at cached mode. You’re literally looking at the data you just migrated. Create a profile for the same user on another machine and the mail file will be empty because at this point there is no data in Exchange, only in the local OST. Another thing to be aware of is that there is no equivalent of an All Documents view in Outlook so make sure your migration tool knows how to migrate unfoldered messages and your users know where to find them in their new mailbox.
Now to my next struggle. Outlook will sync that data to Exchange. It will take between 1 and 3 days to do so. I have tried several tools to speed up the syncing and I would advise you not to bother. The methods they use to populate the Exchange mailbox from a local OST file sidestep much of the standard Outlook sync behaviours meaning information is often missing or, in one case, it sent out calendar invites for every calendar entry it pushed to Exchange. I tried five of those tools and none worked 100%. The risk of missing data or sending out duplicate calendar entries/emails was too high. I opted in the end to stick with Outlook syncing. Unlike Notes replication I can only sync one OST / Outlook mailbox at a time so it’s slow going unless I have multiple client machines. What is nice is that I can do incremental updates quickly once the initial multi-GB mailbox has synced to Exchange.
So my wrestling with the Outlook client boils down to
- Create mail profiles that use cached mode
- Migrate to a local OST
- Use Outlook to sync that to Exchange
- Pay attention to Outlook limits, like a maximum of 500 folders*
- Be Patient
*On Domino mailboxes we migrated that pushed up against the folder or item limits we found Outlook would run out of system memory repeatedly when trying to sync.
One good way to test whether the Exchange data matches the Domino data is to use Outlook Web Access as that is accessing data directly on the Exchange server. Except that’s not as identical to the server data as we are used to seeing with Verse or iNotes. In fact OWA too decides to show you through a browser what it thinks you most need to see versus everything that’s there. Often folders will claim to be empty and that there is no data when in fact that data is there but hasn’t been refreshed by Exchange (think Updall). There are few things more scary in OWA than an empty folder and a link suggesting you refresh from the server. It just doesn’t instill confidence in the user experience.
Finally we have Outlook mobile or even using the native iOS mail application. That wasn’t a separate configuration and unless you configure Exchange otherwise the default is that mobile access will be granted to everyone. In one instance a couple of weeks ago, mobile access suddenly stopped working for all users who hadn’t already set up their devices. When they tried to log in they got invalid name or password. I eventually tracked that down to a Windows update that had changed permissions in Active Directory that Exchange needed set. You can see reference to the issue here, and slightly differently here, although note it seems to have been an issue since Exchange 2010 and still with Exchange 2016. I was surprised it was broken by a Windows update but it was.
I know (and have used) many workarounds for the issues I run into but that’s not for here. Coming from a Domino and Notes background I believe we’ve been conditioned to think in a certain way about mailfile structure, server performance, local data, and the user experience, and expecting to duplicate that exactly is always going to be troublesome.
#DominoForever